
A brand new synthetic intelligence (AI) mannequin has simply been launched achieved results on a human level on a take a look at designed to measure “normal intelligence.”
On December 20, OpenAI’s o3 system acquired a rating of 85% in Reference ARC-AGIeffectively above the AI’s earlier finest rating of 55% and on par with the typical human rating. He additionally carried out effectively on a really tough math take a look at.
Creating synthetic normal intelligence, or AGI, is the said objective of all main AI analysis labs. At first look, OpenAI seems to have at the least taken a big step towards this objective.
Though skepticism stays, many AI researchers and builders consider that one thing has modified. For a lot of, the prospect of AGI now appears extra actual, pressing and nearer than anticipated. Are they proper?
Generalization and intelligence
To grasp what the o3 consequence means, you should perceive what the ARC-AGI take a look at is. In technical phrases, it is a take a look at of the “pattern effectiveness” of an AI system in adapting to one thing new – what number of examples of a brand new state of affairs the system ought to see to grasp the way it works.
An AI system like ChatGPT (GPT-4) will not be very environment friendly on the subject of sampling. It was “educated” on thousands and thousands of examples of human textual content, constructing probabilistic “guidelines” on the most probably phrase mixtures.
The result’s fairly good for widespread duties. It’s dangerous for unusual duties as a result of it incorporates much less knowledge (fewer samples) on these duties.
Till AI techniques can be taught from a small variety of examples and adapt extra effectively, they’ll solely be used for duties which are extremely repetitive and the place occasional failures are tolerable .
The power to precisely remedy beforehand unknown or novel issues from restricted samples of information is called generalization skill. It’s broadly thought of a needed, even basic, factor of intelligence.
Grids and patterns
The ARC-AGI benchmark checks environment friendly pattern becoming utilizing small grid sq. issues just like the one beneath. The AI should perceive the mannequin that transforms the left grid into the proper grid.
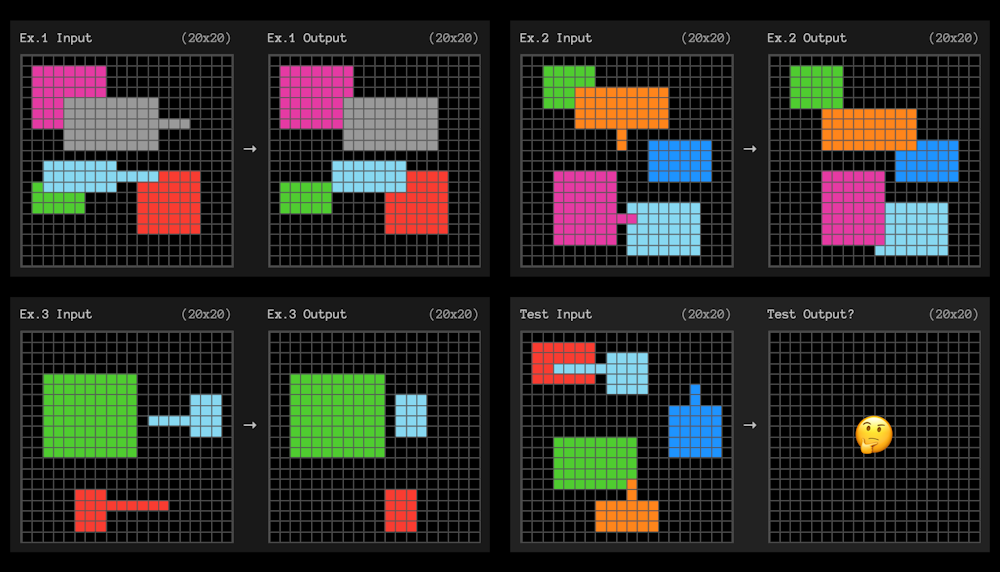
ARC Prize
Every query offers three examples you could be taught from. The AI system should then perceive the principles that “generalize” from the three examples to the fourth.
These are quite a bit just like the IQ checks you typically bear in mind from college.
Weaknesses of the principles and adaptation
We do not know precisely how OpenAI did this, however the outcomes recommend that the o3 mannequin is very adaptable. From just some examples, he finds generalizable guidelines.
To find out a mannequin, we should not make pointless assumptions or be extra exact than we truly have to be. In theoryif you happen to can establish the “weakest” guidelines that do what you need, then you might have maximized your skill to adapt to new conditions.
What will we imply by the weakest guidelines? The technical definition is complicated, however the weakest guidelines are typically these that may be described in simpler statements.
Within the instance above, a easy English expression of the rule may be one thing like: “Any form with a protruding line will transfer to the tip of that line and ‘cowl’ all different shapes with which it overlaps “
On the lookout for thought chains?
Whereas we do not but know the way OpenAI achieved this consequence, it appears unlikely that they intentionally optimized the o3 system to seek out weak guidelines. Nevertheless, to efficiently full the ARC-AGI duties, you must discover them.
We all know that OpenAI began with a general-purpose model of the o3 mannequin (which differs from most different fashions as a result of it may possibly spend extra time “pondering” about tough questions), then educated it particularly to the ARC-AGI take a look at.
French AI researcher François Chollet, who designed the benchmark, believes o3 searches by way of completely different “chains of thought” describing the steps to observe to resolve the duty. It could then select the “finest” based on a vaguely outlined rule, or “heuristic”.
This may be “no completely different” from how Google’s AlphaGo system searched for various attainable transfer sequences to beat the Go world champion.
You’ll be able to consider these thought chains as applications that match the examples. After all, if that is something like Go-playing AI, then it wants a heuristic, or obscure rule, to resolve which program is finest.
There may very well be 1000’s of various seemingly equally legitimate applications generated. This heuristic may very well be “select the weakest” or “select the only”.
Nevertheless, if it is like AlphaGo, then they merely requested an AI to create a heuristic. This was the method for AlphaGo. Google educated a mannequin to charge completely different motion sequences as higher or worse than others.
What we nonetheless do not know
The query then is: is that this actually nearer to AGI? If that is how o3 works, then the underlying mannequin will not be significantly better than earlier fashions.
The ideas that the mannequin learns from language may not be extra appropriate for generalization than earlier than. As an alternative, we might merely be witnessing a extra generalizable “chain of thought” discovered by way of the extra steps of coaching a specialised heuristic for this take a look at. The proof, as at all times, will likely be within the pudding.
Virtually the whole lot about o3 stays unknown. OpenAI has restricted disclosure to a couple media displays and preliminary testing to a handful of AI researchers, labs and safety establishments.
Actually understanding o3’s potential would require in depth work, together with assessments, understanding the distribution of its skills, how usually it fails, and the way usually it succeeds.
When o3 is lastly launched, we’ll know significantly better if he is anyplace close to as adaptable as a median human.
In that case, it might have an enormous revolutionary financial affect, ushering in a brand new period of accelerated, self-enhancing intelligence. We’ll want new benchmarks for the AGI itself and severe consideration of the way it must be ruled.
In any other case, it can nonetheless be a formidable consequence. Nevertheless, day by day life will stay a lot the identical.![]()
Michael Timothy Bennettdoctoral scholar, College of Pc Science, Australian National University And Choose Perrierresearcher on the Stanford Middle for Accountable Quantum Expertise, Stanford University
This text is republished from The conversation underneath Inventive Commons license. Learn the original article.
#OpenAI #claims #mannequin #reached #human #stage #normal #intelligence #take a look at, #gossip247.on-line , #Gossip247
Synthetic Intelligence,Synthetic intelligence,OpenAI ,
chatgpt
ai
copilot ai
ai generator
meta ai
microsoft ai



